Hive, a must known tool for any data engineer

Hive is a data warehouse system built on top of hadoop for allowing querying and managing data sets.
Who ?
Hive was created by Facebook and is currently highly adopted by many firms including Netflix, Facebook and Bookings.
Why ?
Actually not everyone is fond of writing java programs for every problem they have especially data analysts. Hive provides a high level interface through sql like language for processing data through map reduce jobs. This is an important use case especially for business and data analysts. Hive can be somehow slow compared to other systems but at the end it is a trade off.
Hive is also seen as an OLAP system over hadoop.
OLAP (online analytical processing) is computer processing that enables a user to easily and selectively extract and view data from different points of view.
In general Hive is trying to adopt most of the common database concepts and one of them is SQL of course.
The sql interface it is providing is called HiveQL.
Hive Modes
Hive has two execution modes :
- Local
- Map Reduce
In addition Hive can run in interactive mode via Console or batch mode.
Hive Data Units
Databases: The highest data unit.
Tables: similar to database tables. Each table maps to a HDFS directory.
Partitions: follows the same rules of partitioning in databases horizontal scaling. Each partition maps to sub-directories under the table. If most of our queries are focused on peoples of certain countries for example we can partition our data on the country column.
Having too much partitions may
affect the performance of queries that your partitioning isn't targeting heavily in addition to the headache on the Hadoop namenode because of the number of created sub directories.
Buckets: Buckets is very critical to the performance of Hive especially Joins. Buckets handles the issue of having many sub-directories in the case of partitioning by allowing you to specify a fixed number of buckets for your data distribution. The data is hashed and distributed based on that hashing on the predetermined buckets. This guarantees equal sized sub-directories.
Buckets makes sampling much faster as you don't have to go over all the data each time you want to take a sample.
Hive Data Structures
-
Inspired from Java, Hive has normal data types like Integer, Double, Floats, String.
-
In addition, it supports Maps (Associative Arrays), Lists, Structs. This of course makes it more flexible than your normal database.
Architecture
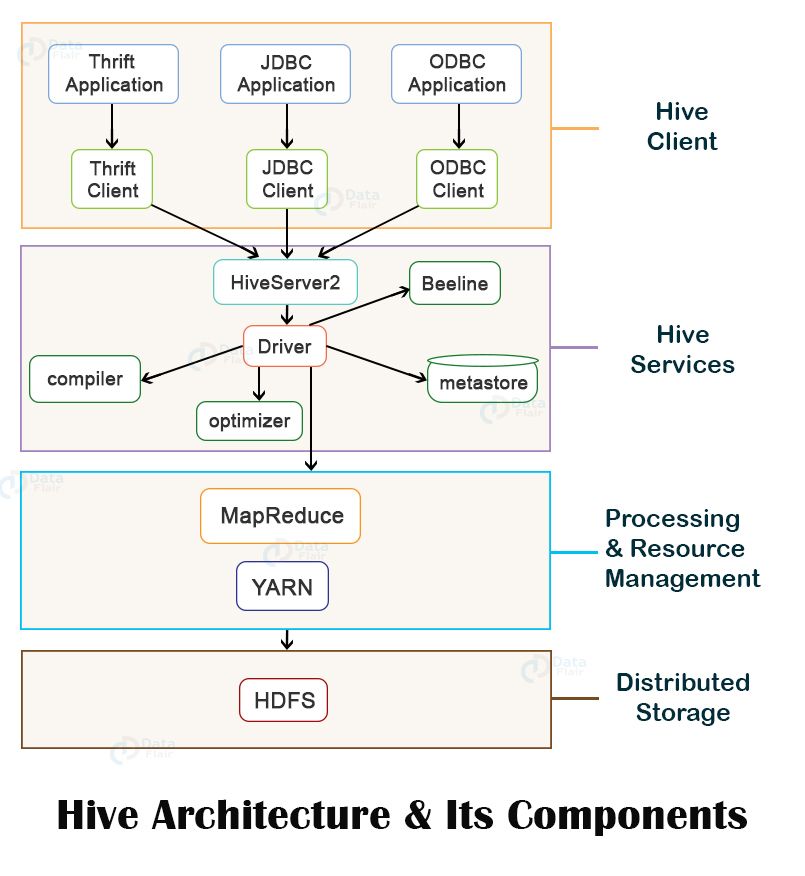
Hive is composed of five major components.
- Shell
- Driver
- Compiler
- Meta Store
- Execution Engine
Database Concepts in Hive
Hive supports the main commands found in ny normal database. It has tables, rows, columns. You can do operations on tables including (Show, Describe, Create, Alter, Truncate and drop)
You can also do Join operation between tables. Different types of join are availalble including OUTER and INNER Join.
Hive supports Views too. The views aren't store in HDFS but on the hive's meta store.
SELECT EMPLOYEE.id as ID, COMPANY.avgSalary
FROM EMPLOYEE JOIN COMPANY ON (EMPLOYEE.company = COMPONY.name)
Example :
CREATE TABLE Employee (id INT, name STRING, company STRING)
PARTITIONED BY (position STRING)
What is different ?
In Hive, you can specify the format of the data while table creation. There are different options (Text File, Parquet, ORC .. etc). Depending on your requirements you can choose what suits you. The default option is Text files.
